TL;DR: I co-trained a summarizer and a generator to learn a compression scheme for text in the same token space as the base model, so it can continue while staying close to full-context behavior on next-token prediction, using an order of magnitude fewer context tokens. Along the way the model discovers its own compression tricks: aggressive pruning, dense punctuation (lots of semicolons), and even occasionally switching into Mandarin to pack more information per token.
State of Context Compaction
We keep asking what kinds of problems LLMs could solve if you just let them think longer—hours, days, weeks. Recent work like OpenAI’s GPT-5.1-Codex-Max and the accelerating science experiments run a model for millions of output tokens on a single objective. If those tokens are all useful, that’s incredible for doing fundamental research and problem solving within engineering, math and science. I'm a strong believer that agents can work for a long time to solve hard problems.
GPT-5.1-Codex-Max (...) is our first model natively trained to operate across multiple context windows through a process called compaction, coherently working over millions of tokens in a single task. This unlocks project-scale refactors, deep debugging sessions, and multi-hour agent loops.
I have no clue how OpenAI’s “compaction” works internally, but there’s a growing body of work on learned context compression. In 2023, we got gist tokens[1]1 Mu et al. "Learning to Compress Prompts with Gist Tokens" NeurIPS: 2023., to train the model to compress a long prompt into learned positions for fixed-size latent compression. Everything has to flow through those positions, forcing the model to learn its own codebook. This means we have to introduce new tokens <GIST_1>, <GIST_2>, ... <GIST_K> to the prompt and compress information into them.
A year later, a NeurIPS paper on rate–distortion prompt compression[2]2 Nagle et al. "Fundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models" NeurIPS: 2024. measured the limits of black box model compression. Their experiments tested if the model could learn to compress prompt of length down to some shorter length , and if it still wanted to solve a downstream task (QA, etc.). They showed you can define a distortion–rate curve where is something like . Below that curve, no hard-prompt compression algorithm can go unless you change the decoder itself. With a frozen LLM, there is a hard limit to how much useful compression you can squeeze out by just dropping / re-ordering tokens.
So, what happens if we don't keep the decoder frozen? What if we let the model invent its own compression scheme jointly with a compressor, but still in the same token space?
Experiment Setup
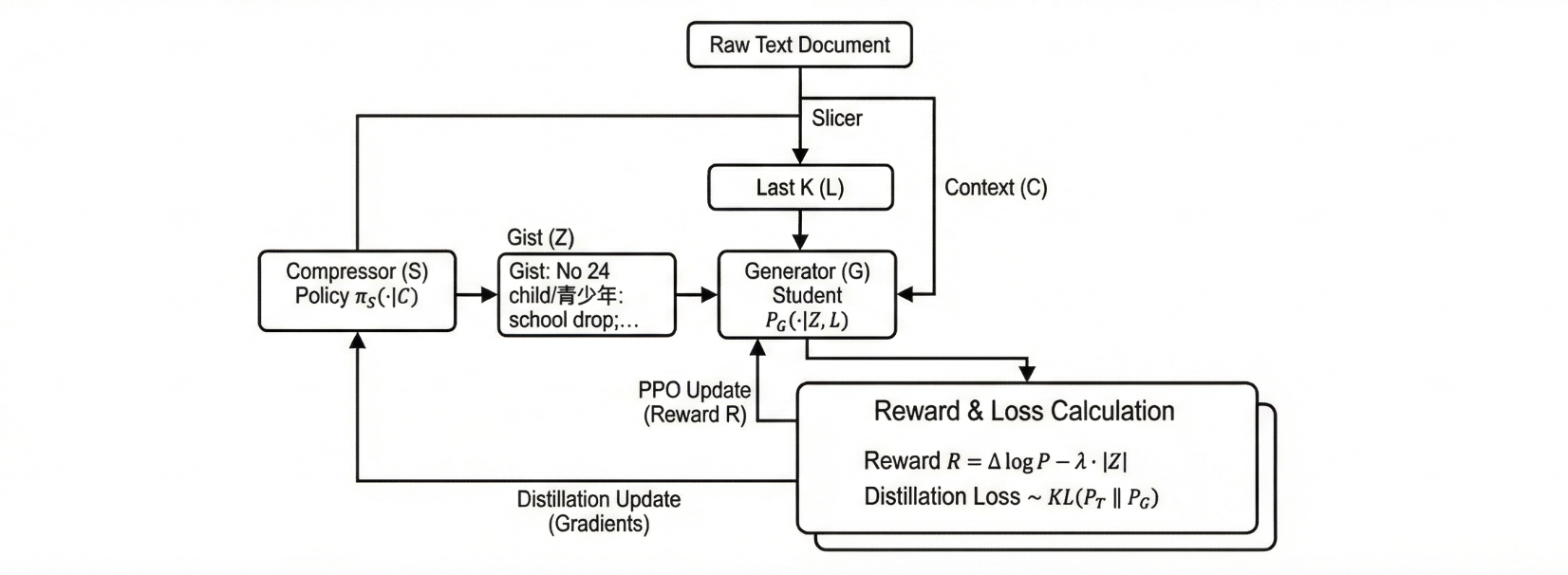
Take a raw text document and slice it into three pieces: is the first 512 tokens (the context), is the next 64 tokens (the future we're trying to predict), and is the last tokens of — the local window we'd naturally have at inference time (e.g., ). We want to learn a compressed representation such that a generator fed can predict almost as well as a teacher model that sees the full . Crucially, lives in the same vocabulary as the base model. No soft tokens. No custom embeddings.
For the dataset, I used samples from the HuggingFaceFW/fineweb-edu dataset, making it difficult for the model to memorize parts of the corpus/encode hyperspecific details, and generalize its summarization policy.
There are three models. The teacher is a fixed (or nearly fixed) model that sees full context: . The generator (or decoder) is a student model that sees the gist plus local context: . Finally, the compressor (or summarizer) is a policy that produces a discrete code: .
GIST:
Z
LAST K TOKENS:
L
CONTINUE:
Y is trained to predict given GIST + LAST_K. A teacher that sees the full acts as our target reference for what good next-token behavior looks like. All three share a tokenizer, so they all see the token sequence in the same way.
Reward Function
We define three quantities. First, the teacher log-prob on the future: . Second, the generator log-prob with last-K only: . This is the baseline—what you get for free from the sliding window. Third, the generator log-prob with gist plus last-K: . The key quantity we care about is the improvement in log-likelihood due to the gist:
If , the compressed code helped the model predict the future better than just local context. Now we introduce a length penalty with a Lagrange multiplier :
This is the scalar reward we give to the compressor . If doesn't help (), then and we naturally punish our summarizer for being long. If helps a lot ( large and positive), it can outweigh the length penalty. By turning the knob, we move along a practical rate–distortion tradeoff, with more rate (longer gists) or less distortion (better predictions).
Early versions of this experiment used a simple binary reward, but we found that the dense, token-level log-prob differences that respect uncertainty and give signal even when multiple continuations are valid were more useful. Reward hacking was also a large problem, where the phrasing of the question itself was used and the size of the gist aggressively declined to 1 token. Instead, it is more valuable to treat this as a constrained optimization problem with next-token prediction as our usefulness and length as the constraint.
Why Feed in the Last Tokens?
An important design decision was to not ask to decode from alone. The input to is:
GIST:
Z
LAST K TOKENS:
L
CONTINUE:
YWhy give it at all? At inference time, you always have a local window—the last chunk of text on the screen. Long-range compression is only needed for what scrolled off the edge. If we didn't give the last tokens, we'd be forcing to redundantly carry both global and very local information, which is wasteful.
Using as baseline is also statistically cleaner. The baseline is just with a regular context window. Then, we can clearly compare how much extra log-probability did the gist buy us and our reward is naturally phrased against a realistic scenario.
Training Loop as Constrained RL
This is a constrained RL problem. The policy is , which outputs a string of at most max_gist_len tokens. The environment is the frozen teacher and the trainable generator . The reward is . The constraint is to keep small—we tune to trade off quality vs compression.
First, gists are sampled from using Tinker's SamplingClient:
sample = await S_sampler.sample_async(
prompt = types.ModelInput.from_ints(prompt_ids),
sampling_params = types.SamplingParams(
max_tokens = config.max_gist_len,
temperature = 1.0,
),
num_samples = 1,
)
z_toks = sample.sequences[0].tokens
z_logprob = sample.sequences[0].logprobsThen, compute log-probs for our teacher on , generator on (GIST + Z + LAST_K + Y) and generator on (LAST_K + Y) using forward_backward_async(..., loss_fn="cross_entropy"). Next, compute per-example reward and use it as the advantage for PPO:
reward = delta_logprob - lambda_len * len(z_tokens)This sets us up to construct PPO datums for with target_tokens = prompt + gist, logprobs = old logprobs for the gist tokens and advantages = 0 on the prompt, reward on the gist tokens. Tinker makes doing forward-backward and optim steps easy:
await S_client.forward_backward_async(rl_datums_S, loss_fn="ppo")
await S_client.optim_step_async(types.AdamParams(learning_rate=1e-5))For , just step the optimizer on the accumulated distillation gradients:
await G_client.optim_step_async(types.AdamParams(learning_rate=2e-5))Because everything is in the same token space and we’re only using Tinker’s primitive ops (sample, forward_backward, optim_step), the whole system ends up being surprisingly simple in code.
Results
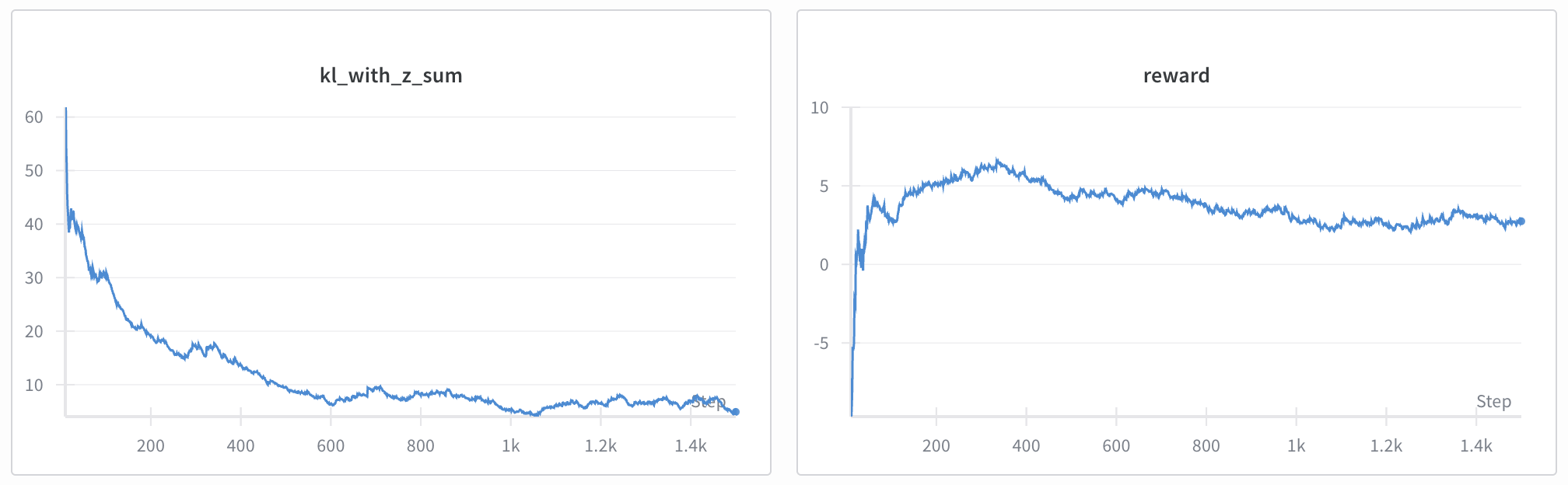
Watching the results of this experiment was incredibly interesting, especially as the methods behind the project evolved. I ran this experiment for 1.5k steps, with the KL between the decoder with summarizer and the ground truth decreasing, and reward staying relatively stable. Ideally, I run this experiment for much longer/larger batch size to watch reward climb with new compression methods. In this specific experiment, I set our maximum length to be 48 tokens, forcing it to be highly efficient with its generations.
In the summaries that were produced, these are the main patterns that I noticed emerge:
- Mandarin tokens were used often to pack more information per token!! This was a super cool result, as the model (Qwen 4B) learned that Chinese characters are more informative than English words in some cases—I'm super curious that if I ran this for much longer, if this would fully converge to a Mandarin translation.
- Aggressive pruning naturally happens! A lot of the time, words like
the,a,and,iswere pruned out, and acronyms were introduced likes.t.instead of "such that". - Numbers were consistently preserved. A huge flaw with soft tokens is how lossy they become w.r.t. storing information like names, numbers, dates, etc. This was also a large regression in some recent multilingual research I worked on. Preserving proper nouns and numbers maximizes the usefulness of the information, as it is hard to infer otherwise.
- Lots of semicolons, em-dashes and other punctuation were introduced to reduce the size of summaries, while still preserving the underlying meaning.
What this means
The summarizer learned to design a summary that was ~9.5% the size of the initial corpus, but our KL between our decoder with Z over the ground truth reduced by an order of magnitude (down to ~0.125 nats/token). This means that our summaries that are produced were actually useful in maintaining the core information of the document at a fraction of the size.
I think forcing the model to compress down 90% from the start may have been a mistake, and we may have seen more information preserved with a 3-4x compression, but I think it's a nice experiment to force the model to figure its way around a very small token space. Almost all of the starting summaries ended mid-sentence, which is a good indicator that it learned to use the space it was given wisely.
Here are a few examples of the summaries produced:
Summary: No.24 child/青少年: school drop; strong 焦虑; hyperactivity nightmares chronic aggression self-harm/ideas; alcohol/drugs; eating/sexual issues 家长先谈, 若持续 to 专业评估
Summary: Household emergency: 3–5 day supplies water 4L/person/day food, meds, docs, cash, radio, batteries, plans, meeting, evac, yearly drills. 减少灾害损失
The outputs did not use Mandarin tokens, which is an indicator that the generated summaries were learned as a code and not influencing the actual output, as a frozen decoder would tend to do if given non-English tokens.
My code is on GitHub for this experiment, as well as a blog on my experience using Tinker and why I absolutely love it and hope more work is done on making RL research faster.
If you are working on interesting RL problems, reach out!
Citation
Please cite this work as:
Rajan Agarwal, "LLMs can invent their own compression", rajan.sh, Nov 2025. https://www.rajan.sh/llm-compressionOr use the BibTeX citation:
@misc{agarwal2025llmcompression,
author = {Rajan Agarwal},
title = {LLMs can invent their own compression},
year = {2025},
howpublished = {rajan.sh},
note = {https://www.rajan.sh/llm-compression},
}