Abstract
Instruction-tuned LLMs underperform on non-Latin scripts because tokenizers explode the input length and decoders never see the right signal. LLINK (Latent Language Injection for Non-English Knowledge) treats the language as a modality: a frozen multilingual encoder reads the text, a contrastive projector drops the sentence vector into a reserved slot, and lightweight adapters teach the decoder to consume that signal. The result is 81% preference over the base model in bilingual QA, without touching the tokenizer or finetuning the decoder from scratch.
Motivation
- Khmer sentences tokenize to 100+ Llama tokens versus 16 in English. That bloats context windows and wastes attention flops before the model even reaches the instruction.
- Parameter-efficient finetunes inherit the tokenizer problem. Instead of teaching the model to cope with junk tokens, we bypass them entirely.
- Treating the language as a modality lets us keep the decoder frozen while still injecting semantically rich context.
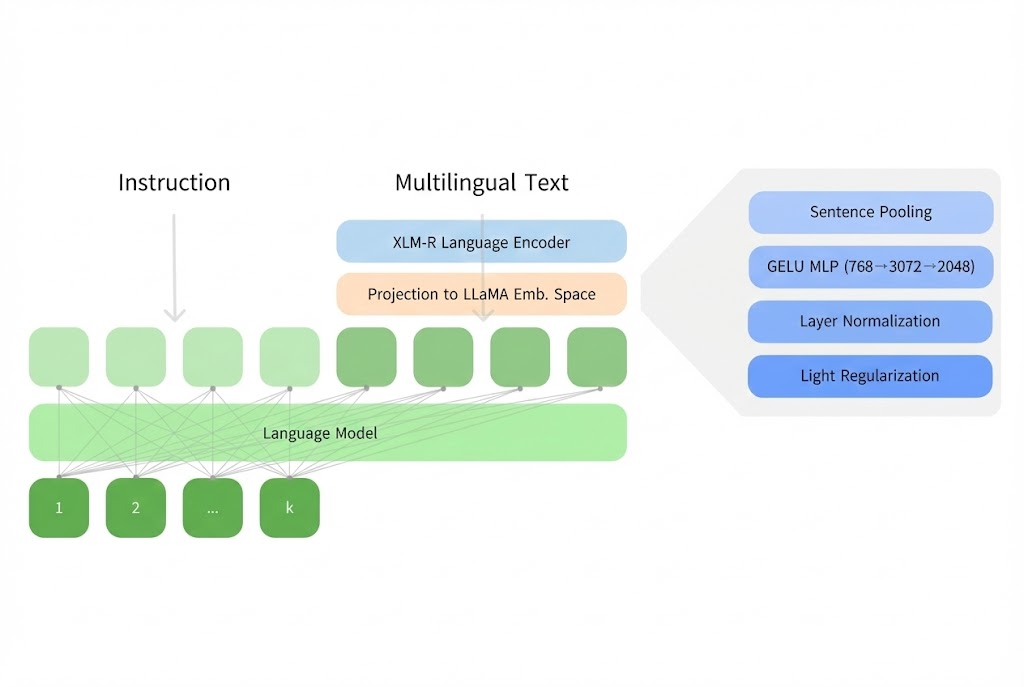
Two-stage pipeline
Stage A · Contrastive alignment
- Encode each sentence with a frozen XLM-R model.
- Project into the decoder’s hidden space at a reserved slot using a lightweight MLP.
- Optimize with symmetric InfoNCE and a large negative queue so the projected vector matches what the decoder expects.
This step alone recovers most of the retrieval gains: recall@1 jumps from 0.10 → 0.43 on ParaCrawl without touching the decoder weights.
Stage B · Slot expansion and usage
- Expand the projected vector into eight soft tokens (f0–f7) that sit in the prompt like ordinary context.
- Train LoRA adapters (rank 16) plus a slot scaler/expander on synthetic instruction-following data.
- Add a usage penalty: every third batch compares the supervised loss with slots zeroed out and penalizes improvements that vanish when the slots are removed.
The penalty is what forces the frozen decoder to actually rely on the injected channel.
Data + training setup
- Stage A: 100k ParaCrawl v2 English–Khmer pairs, 40k holdout for retrieval.
- Stage B: 40k synthetic instructions plus 2k validation, generated by prompting a 70B teacher with the English reference.
- Inputs are clamped to 12–256 Khmer characters to keep the encoder fast; the reserved slot always appears in the prompt template.
Results
| Benchmark | Metric | Baseline | LLINK |
|---|---|---|---|
| Retrieval | Recall@1 | 0.10 | 0.45 |
| Retrieval | Recall@5 | 0.31 | 0.72 |
| LLM-as-judge (understanding) | Win rate | 26% | 74% |
| LLM-as-judge (Q&A) | Win rate | 36% | 51% |
Token budget also improves: Khmer prompts compress from 100+ decoder tokens to eight soft slots, cutting decoder compute roughly 3× while amortizing one encoder pass.
Architecture callout
Khmer text → frozen XLM-R → contrastive projector → reserved decoder slot → slot expander → frozen Llama decoder.
A final normalization matches the slot norms to the median embedding norm so the decoder treats the injected tokens as native context.
Failure modes
- Numeric fidelity still drifts; multilingual encoders cluster numbers tightly so the slots sometimes blur quantities.
- Literal translation remains the hardest setting because the slot compression omits certain morphemes.
- Usage penalty helps, but extremely terse prompts can cause the decoder to fall back to English defaults.
Future work
- Extend the slot interface to right-to-left and logographic scripts; they may require larger K or separate projectors.
- Predict slot count dynamically so short prompts get two to four tokens while dense documents receive a wider channel.
- Add copy-aware objectives so exact numbers and named entities survive the injection process.
Citation
Please cite this work as:
Rajan Agarwal and Aarush Gupta, "LLINK: Cross Lingual Alignment via Encoder Injection", rajan.sh, 2025. https://www.rajan.sh/llinkOr use the BibTeX citation:
@misc{agarwal2025llink,
author = {Rajan Agarwal and Aarush Gupta},
title = {LLINK: Cross Lingual Alignment via Encoder Injection},
year = {2025},
howpublished = {rajan.sh},
note = {https://www.rajan.sh/llink},
}